



The Cerebras Wafer Scale Engine, The Largest Chip Ever Built, Transforms the Artificial Intelligence Landscape with Unprecedented Compute Density
LOS ALTOS, Calif. — (BUSINESS WIRE) — August 19, 2019 — Cerebras Systems, a startup dedicated to accelerating Artificial intelligence (AI) compute, today unveiled the largest chip ever built. Optimized for AI work, the Cerebras Wafer Scale Engine (WSE) is a single chip that contains more than 1.2 trillion transistors and is 46,225 square millimeters. The WSE is 56.7 times larger than the largest graphics processing unit which measures 815 square millimeters and 21.1 billion transistors1. The WSE also contains 3,000 times more high speed, on-chip memory, and has 10,000 times more memory bandwidth.
This press release features multimedia. View the full release here: https://www.businesswire.com/news/home/20190819005148/en/
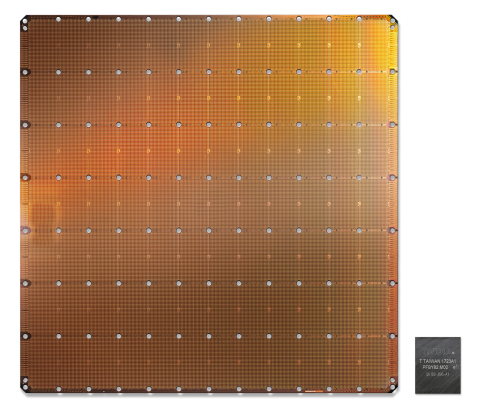
The Cerebras Wafer-Scale Engine (WSE) is the largest chip ever built. It measures 46,225 square millimeters and includes 1.2 trillion transistors. Optimized for artificial intelligence compute, the WSE is shown here for comparison alongside the largest graphics processing unit. (Photo: Business Wire)
In AI, chip size is profoundly important. Big chips process information more quickly, producing answers in less time. Reducing the time-to-insight, or “training time,” allows researchers to test more ideas, use more data, and solve new problems. Google, Facebook, OpenAI, Tencent, Baidu, and many others argue that the fundamental limitation to today’s AI is that it takes too long to train models. Reducing training time removes a major bottleneck to industry-wide progress.
“Designed from the ground up for AI work, the Cerebras WSE contains fundamental innovations that advance the state-of-the-art by solving decades-old technical challenges that limited chip size—such as cross-reticle connectivity, yield, power delivery, and packaging,” said Andrew Feldman, founder and CEO of Cerebras Systems. “Every architectural decision was made to optimize performance for AI work. The result is that the Cerebras WSE delivers, depending on workload, hundreds or thousands of times the performance of existing solutions at a tiny fraction of the power draw and space.”
These performance gains are accomplished by accelerating all the elements of neural network training. A neural network is a multistage computational feedback loop. The faster inputs move through the loop, the faster the loop learns or “trains.” The way to move inputs through the loop faster is to accelerate the calculation and communication within the loop.
With an exclusive focus on AI, the Cerebras Wafer Scale Engine accelerates calculation and communication and thereby reduces training time. The approach is straightforward and is a function of the size of the WSE: With 56.7 times more silicon area than the largest graphics processing unit, the WSE provides more cores to do calculations and more memory closer to the cores so the cores can operate efficiently. Because this vast array of cores and memory are on a single chip, all communication is kept on-silicon. This means the WSE’s low-latency communication bandwidth is immense, so groups of cores can collaborate with maximum efficiency, and memory bandwidth is no longer a bottleneck.
The 46,225 square millimeters of silicon in the Cerebras WSE house 400,000 AI-optimized, no-cache, no-overhead, compute cores and 18 gigabytes of local, distributed, superfast SRAM memory as the one and only level of the memory hierarchy. Memory bandwidth is 9 petabytes per second. The cores are linked together with a fine-grained, all-hardware, on-chip mesh-connected communication network that delivers an aggregate bandwidth of 100 petabits per second. More cores, more local memory and a low latency high bandwidth fabric together create the optimal architecture for accelerating AI work.
“While AI is used in a general sense, no two data sets or AI tasks are the same. New AI workloads continue to emerge and the data sets continue to grow larger,” said Jim McGregor, principal analyst and founder at TIRIAS Research. “As AI has evolved, so too have the silicon and platform solutions. The Cerebras WSE is an amazing engineering achievement in semiconductor and platform design that offers the compute, high-performance memory, and bandwidth of a supercomputer in a single wafer-scale solution.”
For many years, Cerebras has been collaborating closely with TSMC, the world’s largest semiconductor foundry and leader in advanced process technologies. The WSE is manufactured by TSMC on its advanced 16nm process technology.
“TSMC has long partnered with the industry innovators and leaders to manufacture advanced processors with leading performance. We are very pleased with the result of our collaboration with Cerebras Systems in manufacturing the Cerebras Wafer Scale Engine, an industry milestone for wafer scale development,” said JK Wang, TSMC Senior Vice President of Operations. “TSMC’s manufacturing excellence and rigorous attention to quality enables us to meet the stringent defect density requirements to support the unprecedented die size of Cerebras’ innovative design.”
More Cores, More Memory Close to Cores, More Low Latency Communication Bandwidth
Cores
The WSE contains 400,000 AI-optimized compute cores. Called SLAC™ for Sparse Linear Algebra Cores, the compute cores are flexible, programmable, and optimized for the sparse linear algebra that underpins all neural network computation. SLAC’s programmability ensures cores can run all neural network algorithms in the constantly changing machine learning field.
Because the Sparse Linear Algebra Cores are optimized for neural network compute primitives, they achieve industry-best utilization—often triple or quadruple that of a graphics processing unit. In addition, the WSE cores include Cerebras-invented sparsity harvesting technology to accelerate computational performance on sparse workloads (workloads that contain zeros) like deep learning.
Zeros are prevalent in deep learning calculations: often, the majority of the elements in the vectors and matrices that are to be multiplied together are zero. And yet multiplying by zero is a waste of silicon, power, and time. No new information is made.
Because graphics processing units and tensor processing units are dense execution engines—engines designed to never encounter a zero—they multiply every element even when it is zero. When 50 to 98 percent of the data are zeros, as is often the case in deep learning, most of the multiplications are wasted. Imagine trying to run forward quickly, when most of your steps don’t move you toward the finish line. The Cerebras Sparse Linear Algebra Cores never multiply by zero. All zero data is filtered out and can be skipped in the hardware. Instead, useful work is done in its place.
Memory
Memory is a key component of every computer architecture. Memory closer to compute translates to faster calculation, lower latency, and better power efficiency for data movement. High-performance deep learning requires massive compute with frequent access to data. This requires close proximity between the compute cores and memory. This is not the case in graphics processing units where the vast majority of the memory is slow and far away (off-chip).
The Cerebras Wafer Scale Engine includes more cores, with more local memory, than any chip in history. This enables fast, flexible computation, at lower latency and with less energy. The WSE has 18 Gigabytes of on-chip memory accessible by its core in one clock cycle. The collection of core-local memory aboard the WSE delivers an aggregate of 9 petabytes per second of memory bandwidth—this is 3,000 X more on-chip memory and 10,000 X more memory bandwidth than the leading graphics processing unit has.
Communication Fabric
Swarm™ communication fabric, the interprocessor communication fabric used on the WSE, achieves breakthrough bandwidth and low latency at a fraction of the power draw of the traditional communication techniques. Swarm provides a low-latency, high-bandwidth, 2D mesh that links all 400,000 cores on the WSE with an aggregate 100 petabits per second of bandwidth. Swarm supports single-word active messages that can be handled by receiving cores without any software overhead. Routing, reliable message delivery, and synchronization are handled in hardware. Messages automatically activate application handlers for every arriving message.
Swarm provides a unique, optimized communication path for each neural network. Software configures the optimal communication path through the 400,000 cores to connect processors according to the structure of the particular user-defined neural network being run.
Swarm’s results are industry-defining. Typical messages traverse one hardware link with nanosecond latency. The aggregate bandwidth across a Cerebras WSE is measured is 100 petabits per second. Communication software such as TCP/IP and MPI are not needed, so their performance penalties are avoided. The energy cost of communication in this architecture is well under one picojoule per bit, which is nearly two orders of magnitude lower than in graphics processing units. With the rare combination of massive bandwidth and exceptionally low latency, the Swarm communication fabric enables the Cerebras WSE to learn faster than all available alternative solutions.




 Animation, 3D Art and 3D Models")